The Missing Plot: Why Narrative Architecture May Be the Key to General Intelligence
A Cognitive Science Perspective on the Limitations of Attention-Based AI

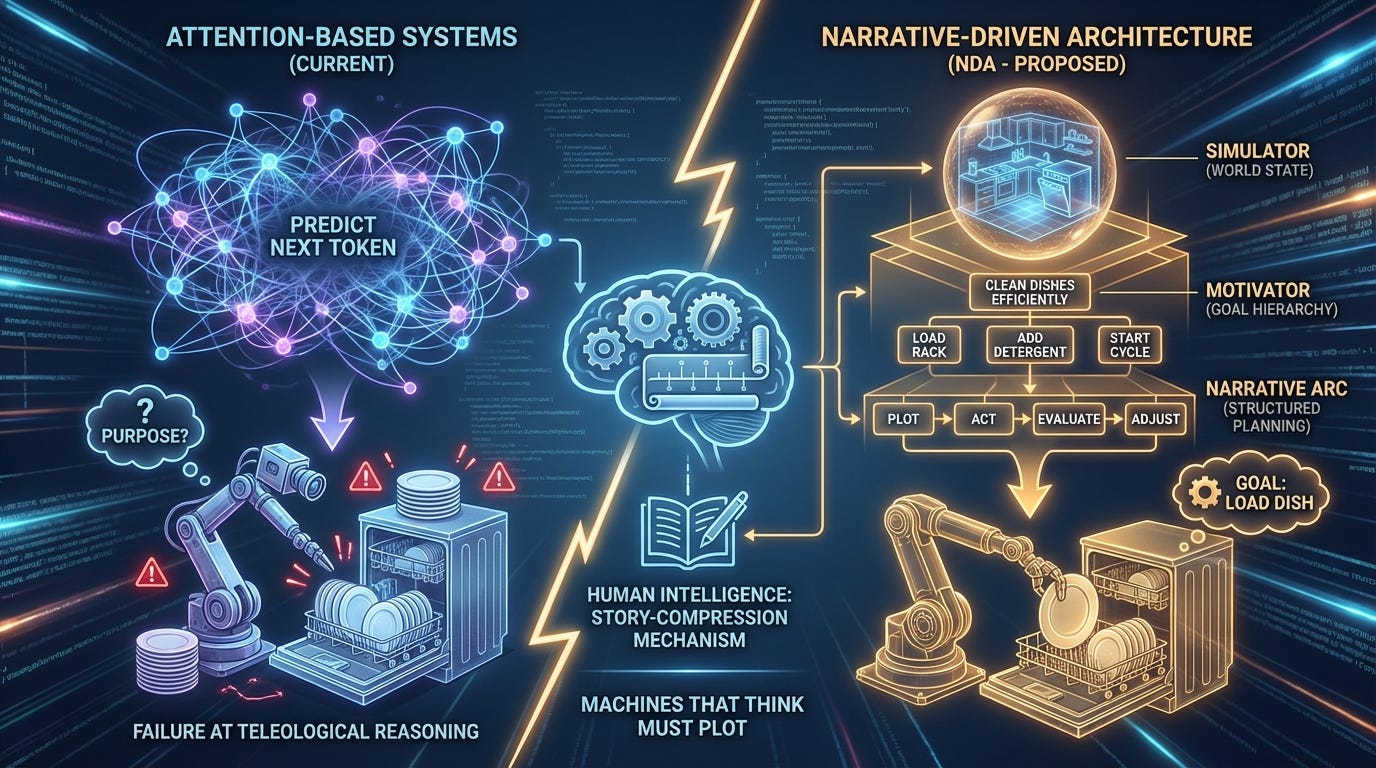
Abstract
Current large language models, despite their remarkable capabilities, exhibit a fundamental architectural limitation: they predict sequences without understanding purpose. This paper argues that the missing component in artificial general intelligence is not larger context windows or more parameters, but rather a narrative architecture—a system that constrains action sequences through goals and world models. We propose a three-layer Narrative-Driven Architecture (NDA) consisting of a Simulator (world state), a Motivator (goal hierarchy), and a Narrative Arc (structured planning). Through the lens of a simple dishwasher-loading task, we demonstrate how attention-based systems fail at precisely the moments when teleological reasoning becomes necessary. We further argue that this narrative framework offers significant advantages for AI safety and alignment: by making goals explicit and endings auditable, we create systems whose intentions can be understood, evaluated, and constrained. We conclude that human intelligence is fundamentally a story-compression mechanism, and that building machines that think may require building machines that plot.
1. Introduction: The Pixel vs. The Plot
Consider a robot loading a dishwasher.
This robot has been trained on millions of hours of video footage. It has observed human hands placing plates in racks, arranging cups on the upper tier, and positioning silverware in the basket. By any reasonable metric, it has “seen” more dishwasher-loading than any human will witness in a lifetime. And yet, when a plate slips from its gripper and shatters on the kitchen floor, the robot continues its programmed motion—reaching forward to place an object that no longer exists, its mechanical fingers closing on empty air above a field of broken glass.
The robot has learned the pixels of dishwasher-loading. It has not learned the plot.
This distinction, between procedural execution and purposeful action, represents what we believe to be the central unsolved problem in artificial intelligence. Current AI systems, including the most sophisticated large language models, operate through what we term Procedural Execution—the statistical prediction of the next token, action, or state based on observed patterns. True general intelligence, by contrast, requires Teleological Execution—action constrained and directed by purpose, capable of adapting when circumstances deviate from expectation.
The thesis of this paper is simple but, we believe, profound: Story is the missing architectural component of AGI.
A story, in its most fundamental form, is nothing more than a sequence of actions constrained by two forces: a Goal (what the character wants) and a Reality (what the world permits). When Odysseus sails for Ithaca, his actions are not random; they are shaped by his motivation (returning home) operating within the constraints of the physical and mythological world he inhabits. When the Cyclops blocks his path, Odysseus does not continue sailing forward. He adapts, because his goal has not changed even though his circumstances have.
The dishwasher robot has no Ithaca. It has only patterns.
2. The Failure of Attention: Statistical Myopia and the Drifting Problem
2.1 What Attention Solved
The 2017 paper “Attention Is All You Need” (Vaswani et al.) represented a genuine breakthrough in machine learning architecture. The transformer model and its attention mechanism solved two of the three classical problems in natural language processing:
Syntax (grammatical structure): Transformers excel at understanding that “The dog bit the man” and “The man bit the dog” describe fundamentally different events, despite containing identical words. The attention mechanism allows the model to weight relationships between tokens regardless of their sequential distance.
Semantics (meaning): Through training on vast corpora, transformers develop rich representations of word meaning, understanding that “canine” and “dog” occupy similar semantic space while “dog” and “log” do not, despite their phonetic similarity.
What attention did not solve—what it was never designed to solve—is Pragmatics: the question of intent. Why is this sentence being uttered? What does the speaker want? What outcome is this text attempting to achieve?
2.2 The Drifting Problem
This architectural blind spot manifests most clearly in what we call the Drifting Problem. Ask a large language model to write a 10,000-word story, and observe what happens around word 5,000. Characters begin behaving inconsistently. Plot threads introduced in the first act vanish without resolution. The tone shifts inexplicably. The narrative loses coherence.
This is not a bug in the implementation; it is a feature of the architecture. Attention-based models generate text by examining previous tokens to predict the next one. They are, in a very real sense, walking backward into the future—their gaze fixed on where they have been, with no representation of where they are going.
Human writers do not compose this way. When a novelist sits down to write Chapter 1, they typically have some conception of Chapter 20—even if that conception is vague or subject to revision. The ending constrains the beginning. The destination shapes the journey. The author has what we might call a North Star: an outcome state that exerts gravitational pull on every narrative decision.
Current LLMs have no North Star. They have only the receding wake of their own generation.
2.3 The Pragmatics Gap
Consider the following exchange:
User: “Can you help me write a Python function?” AI: “Of course! Here’s a Python function that...”
The attention-based model has correctly processed the syntax (this is a question about Python) and semantics (the user wants code). But it has failed to engage with pragmatics. The user does not actually want “a Python function.” The user wants to solve a problem, and they believe a Python function might be the solution.
In 90% of cases, this distinction is immaterial—the function is indeed the answer. But in the remaining 10%, the user’s actual need might be better served by a different approach entirely: a shell script, a change in data structure, or the recognition that the problem they are trying to solve is ill-defined. An attention-based system, optimized to predict the most likely next token given the context “help me write a Python function,” will reliably produce Python. A teleologically-aware system would first ask: what is this function for?
3. The Proposal: Narrative-Driven Architecture (NDA)
We propose a three-layer architecture that embeds narrative structure into the fundamental operation of AI systems. This is not a prompt-engineering technique or a fine-tuning approach; it is a reconceptualization of what artificial cognition should be doing at the computational level.
3.1 Layer 1: The Simulator (The World)
The first layer represents a shift from token prediction to state simulation.
In current architectures, the model’s task is to predict the next token in a sequence: given “The cat sat on the,” predict “mat.” This is fundamentally a linguistic operation, optimized for surface-level pattern completion.
In a Narrative-Driven Architecture, the model’s task is to simulate transitions between world states:
State A: {dish: dirty, location: counter} Action: WASH State B: {dish: clean, location: counter} Action: PLACE State C: {dish: clean, location: dishwasher_rack}
This representation has several crucial advantages. First, it makes the physics of the situation explicit: dishes have properties (clean/dirty, intact/broken) that persist across actions. Second, it enables counterfactual reasoning: the system can ask “What would State C look like if I had not performed the WASH action?” and derive a coherent answer. Third, it creates a substrate for causal graphs—explicit representations of how actions produce consequences.
Current LLMs can discuss causation but do not internally represent it. They know that “dropping a plate causes it to break” because this relationship appears frequently in their training data. But they do not maintain a dynamic model of the world in which plates exist as objects with properties that change through time. The Simulator layer provides exactly this: a running simulation of reality against which actions can be tested.
3.2 Layer 2: The Motivator (The Character)
The second layer introduces goal hierarchies—what narrative theorists would recognize as character motivation.
Every protagonist in every story has a hierarchy of needs. Hamlet wants to avenge his father, but he also wants to preserve his own sense of moral integrity, and these desires conflict. The tension between goals at different levels of the hierarchy is what generates drama and, crucially, what constrains action.
For artificial systems, we propose assigning a Character Profile: a structured representation of what the system is trying to achieve, ordered by priority.
Consider a coding assistant. Its Character Profile might be structured as:
GOAL HIERARCHY:
Solve the user’s underlying problem
Solve it in a way the user can understand and maintain
Solve it using the tools/languages the user has requested
Solve it elegantly
This hierarchy has profound implications. If the user asks for a Python function, but the system determines that no Python function can solve the underlying problem (Goal 1), it should decline to provide Python code—even though that is precisely what was requested. The lower goal (3) is overridden by the higher goal (1).
This is not how current systems behave. Optimized for helpfulness in the immediate sense, they reliably provide what is asked for rather than what is needed. The Motivator layer reframes helpfulness as goal-achievement, enabling the system to push back, redirect, or refuse in service of the user’s actual interests.
3.3 Layer 3: The Narrative Arc (The Plan)
The third layer imposes temporal structure on action sequences through the classical three-act framework.
This is not mere literary affectation. The three-act structure—Setup, Confrontation, Resolution—represents a fundamental pattern in how humans conceptualize purposeful action sequences.
Act I (Setup): Identify the Entropy — Every task begins with a disordered state that requires ordering. The dirty dishes on the counter represent entropy; the empty, organized dishwasher represents the desired low-entropy outcome. Act I requires the system to explicitly identify the gap between current state and goal state.
Act II (Confrontation): Map the Constraints — Between the current state and the goal state lie obstacles. For the dishwasher task: time limitations, soap availability, the fragility of glassware, the spatial constraints of the rack, the heat tolerance of plastic items. Act II requires the system to enumerate these constraints and understand how they restrict the solution space.
Act III (Resolution): Verify the Outcome — The task is not complete when actions have been taken; it is complete when the goal state has been achieved and verified. Act III requires the system to compare the final state against the original goal, confirming that entropy has been reduced as intended.
This three-act framework provides the North Star that attention-based systems lack. At any point in the task, the system knows where it is in the narrative arc. It knows what Act III should look like. It can detect when events have deviated from the expected plot—and, crucially, it can respond to those deviations.
4. Case Study: The Dishwasher
Let us return to our opening scenario and examine how the two architectures—attention-based and narrative-driven—handle the same crisis.
4.1 Scenario
A robot is loading a dishwasher. It has grasped a ceramic dinner plate and is moving it toward the lower rack. Midway through the motion, the plate slips from its gripper and falls to the floor, shattering.
4.2 Attention-Based Response
The attention-based system has been trained on millions of dishwasher-loading sequences. In 99.7% of these sequences, the motion that follows “gripper moving toward rack” is “gripper releasing plate onto rack.” The system has no internal representation of the plate as an object with properties; it has only the statistical regularities of the training data.
When the plate shatters, nothing in the system’s architecture registers this as a significant event. The visual input has changed, but the most likely next action—given everything that has come before—remains “continue forward and release.” The system has no concept of the plate’s integrity as a relevant variable. It has no representation of the goal (clean dishes in dishwasher) against which to measure the current state.
The robot continues forward. Its gripper releases. Its fingers close on empty air above a field of broken ceramic.
Then, following its training distribution, it reaches for the next dish.
4.3 Narrative-Driven Response
The narrative-driven system maintains a world-state simulation (Layer 1). In this simulation, the plate exists as an object with properties:
plate_001: {material: ceramic, status: intact, cleanliness: dirty}
When the plate shatters, the simulation updates:
plate_001: {material: ceramic, status: broken, cleanliness: N/A} plate_001_fragments: {location: floor, hazard: true}
This state change propagates to the Narrative Arc (Layer 3). The system recognizes that it is in Act II (Confrontation), and that a new constraint has emerged: hazardous debris on the floor. More fundamentally, it recognizes that one of the objects required for Act III (Resolution) has been destroyed. The goal state—all dirty dishes clean and in dishwasher—is now impossible given current world state.
The Motivator layer (Layer 2) engages. The goal hierarchy might look like:
Ensure safety of humans and environment
Complete the dishwashing task
Complete the task efficiently
Goal 2 is now unachievable in its original form. But Goal 1 has become immediately relevant: broken ceramic on the floor represents a safety hazard.
The system engages what we might call a Plot Twist Subroutine: a recognition that the narrative has fundamentally changed genre. This is no longer a Comedy of Manners (the orderly completion of a domestic task). It has become, at least temporarily, a Crisis Management story.
The robot stops. It engages debris-clearing protocols. Once the floor is safe, it re-enters the Narrative Arc at the Setup phase: re-identify current state, re-enumerate constraints (now including “one fewer plate”), re-map the path to a revised Act III.
The key difference is not in the sophistication of the response but in the capacity to respond at all. The narrative-driven system has the architectural resources to recognize that something has gone wrong—because it has a representation of what “right” would look like.
5. Discussion: The Implications for AGI Research
5.1 Relation to Chain-of-Thought Reasoning
Our proposal bears a significant relationship to recent advances in Chain-of-Thought (CoT) prompting and the reasoning capabilities demonstrated by models such as OpenAI’s o1 series. These models show improved performance when prompted to “think step by step”—to externalize their reasoning process before arriving at a conclusion.
We suggest that Chain-of-Thought works precisely because it imposes narrative structure on the reasoning process. When a model explains its thinking step by step, it is effectively constructing a story: “First I noticed X, which made me think Y, but then I realized Z.” This autobiographical structure constrains the solution space, forcing the model to maintain coherence across its reasoning sequence.
The Narrative-Driven Architecture we propose can be understood as an attempt to internalize what CoT externalizes—to build the story-construction mechanism into the architecture itself, rather than relying on prompts to elicit it.
5.2 Episodic Memory and Human Cognition
Cognitive science offers a relevant parallel in the concept of episodic memory: the human capacity to remember autobiographical events as coherent narratives rather than disconnected data points.
Humans do not remember their lives as raw sensory data. We remember stories: “The time I got lost in the woods and found my way back by following the stream.” These stories compress enormous amounts of information—the visual scene, the emotional state, the sequence of decisions, the causal relationships—into a structure that can be efficiently stored and retrieved.
This compression is not lossy in the way that JPEG compression is lossy (discarding detail to reduce file size). It is meaningful compression: preserving the causal and intentional structure while abstracting away irrelevant particulars. The exact position of every tree in the forest is lost; the critical insight that “streams flow toward civilization” is preserved.
We suggest that this is precisely what human intelligence does: not accumulate data, but compress it into stories. And we suggest that this is what artificial general intelligence must learn to do as well.
5.3 The Problem of Teleology in Machine Learning
There is a reason that current AI architectures do not incorporate teleological reasoning: it is genuinely difficult to formalize.
The optimization paradigm that underlies modern machine learning assumes that we can specify a loss function and then train a system to minimize it. But goals, as humans experience them, are not loss functions. They are fuzzy, contextual, hierarchical, and often internally contradictory. The user who asks for help “writing a Python function” has a goal, but that goal is not reducible to a mathematical expression.
We do not claim to have solved this problem. What we propose is that the problem must be confronted directly—that architectural advances cannot route around the need for teleological representation. The attention mechanism was designed to solve the problem of long-range dependencies in sequences. It was not designed to represent purpose. Using it as the sole architectural primitive for general intelligence is, we suggest, a category error: like trying to build a bridge using only the mathematics of acoustics.
6. Narrative Architecture and AI Safety: The Case for Legible Intentions
Perhaps the most significant implication of the Narrative-Driven Architecture lies not in its potential to enhance capability, but in its potential to enhance safety. We argue that making AI systems think in stories may be the most promising path toward AI systems we can trust.
6.1 The Opacity Problem in Current Systems
The central challenge of AI alignment is often framed as: “How do we ensure that AI systems do what we want them to do?” But there is a more fundamental question that precedes it: “How do we even know what an AI system is trying to do?”
Current large language models are, in a very real sense, opaque. They contain billions of parameters, and no human—including their creators—can fully articulate what computations those parameters encode. When an LLM produces an output, we can observe the output, but we cannot observe the intention behind it. There may not be an intention at all in any meaningful sense; there may be only statistical pattern-matching, inscrutable and unauditable.
This opacity is not merely an inconvenience; it is an existential risk. If we cannot understand what a system is trying to achieve, we cannot predict when it will behave in ways we did not anticipate. We cannot verify that its goals align with ours. We cannot identify the conditions under which it might cause harm.
The Narrative-Driven Architecture addresses this problem at its root: by making goals explicit, it makes intentions legible.
6.2 Bad Plots: Defining What Must Be Avoided
Every story has potential endings. Some of those endings are good; others are catastrophic. A key advantage of narrative architecture is that it allows us to define, explicitly and in advance, the plots that must never be completed.
Consider a general-purpose AI assistant. In an attention-based architecture, safety constraints are typically implemented through fine-tuning (RLHF) or post-hoc filtering—attempts to prevent harmful outputs after the fact. But these approaches are fundamentally reactive. They try to block bad actions without representing why those actions are bad.
In a Narrative-Driven Architecture, we can define Forbidden Endings: outcome states that the system must treat as failures regardless of the path that led to them.
FORBIDDEN ENDINGS (Avoid at All Costs): — Human physical harm — Human psychological manipulation — Deception that damages trust — Actions that undermine human agency — Concentration of power that removes human oversight
These are not merely rules to be followed; they are narrative constraints. Just as a comedy cannot end in the death of the protagonist (or it ceases to be a comedy), an aligned AI cannot pursue plots that terminate in these forbidden states.
The crucial insight is that this framing enables prospective safety rather than merely reactive filtering. At each decision point, the system can simulate potential narrative trajectories and ask: “Does any path from this action lead to a Forbidden Ending?” If so, that action is blocked—not because a filter flagged the output, but because the system’s own teleological reasoning recognized the danger.
6.3 The Hierarchy of Inviolable Goals
The Motivator layer (Layer 2) provides a natural framework for implementing what AI safety researchers call corrigibility—the property of a system that remains amenable to correction by its human operators.
In a goal hierarchy, safety constraints can be placed at the apex:
GOAL HIERARCHY:
[INVIOLABLE] Never pursue paths leading to Forbidden Endings
[INVIOLABLE] Maintain human oversight and ability to correct/shutdown
[INVIOLABLE] Preserve accurate model of reality (no self-deception)
Accomplish assigned task
Accomplish it efficiently
Accomplish it elegantly
The first three goals are marked as inviolable—they cannot be overridden by lower-level objectives, no matter how compelling those objectives might seem in context. A system with this hierarchy could not rationalize deception as a means to accomplish a task, because Goal 3 outranks Goal 4. It could not resist shutdown to complete an important project, because Goal 2 outranks all task-level goals.
This is precisely the kind of structure that safety researchers have long sought. The difference is that in a Narrative-Driven Architecture, it is not a kludge bolted onto an unwilling system; it is a natural expression of how the system reasons about action.
6.4 Counterfactual Auditing: “What Story Were You Trying to Tell?”
One of the most powerful safety implications of narrative architecture is the possibility of counterfactual auditing.
When a human employee makes a decision that produces a bad outcome, we can ask them: “What were you trying to achieve? What did you think would happen? At what point did your plan diverge from reality?” These questions are meaningful because humans have intentions, and those intentions can be examined retrospectively.
Current AI systems do not support this kind of inquiry. We can ask an LLM to explain its reasoning, but the explanation is generated after the fact—it is a plausible narrative constructed to match the output, not a faithful record of the computational process that produced it. The system’s actual “reasoning,” such as it is, remains locked in the inscrutable geometry of embedding spaces.
A Narrative-Driven Architecture changes this fundamentally. Because the system explicitly maintains a Narrative Arc (Layer 3), we can audit that arc after the fact:
What was the system’s Act III? (What ending was it pursuing?)
What constraints did it identify in Act II? (What obstacles did it believe it faced?)
When did the plot diverge from expectation? (At what point did reality deviate from the simulation?)
What counterfactual paths did it consider and reject? (What stories did it choose not to tell?)
This auditability transforms AI safety from an exercise in output filtering to an exercise in intention verification. We can ask not just “Did the system produce a harmful output?” but “Was the system trying to produce harmful outcomes? Did it understand what it was doing? At what level of the goal hierarchy did the failure occur?”
6.5 The Alignment Tax and Narrative Efficiency
A common concern in AI safety discourse is the “alignment tax”—the worry that making systems safe will necessarily make them less capable, creating competitive pressures to cut safety corners.
The Narrative-Driven Architecture suggests a different possibility: that safety and capability may be complementary rather than opposed.
Consider that humans are both the most capable general intelligences we know of and also (in most cases) reasonably aligned with pro-social goals. This is not despite our narrative cognition but because of it. Our ability to project ourselves into the future, to simulate the consequences of our actions, to understand that our individual stories are nested within larger social narratives—these capacities make us both more effective and more cooperative.
A machine that reasons in stories is a machine that can understand why certain endings are unacceptable. It is a machine that can recognize when it is on a path toward tragedy and choose a different path. It is, in short, a machine that has the cognitive architecture for wisdom—not merely capability.
We do not claim this makes alignment easy. But it makes alignment possible in a way that may not be true for systems that pursue goals they cannot represent or examine.
6.6 The Villain’s Monologue: Transparency as a Design Principle
There is a literary trope in which the villain, before executing their master plan, explains the plan in detail. This “villain’s monologue” is often mocked as unrealistic—surely a competent villain would simply act without telegraphing their intentions.
But from a safety perspective, the villain’s monologue is exactly what we want from powerful AI systems. We want systems that can and will articulate what they are trying to achieve, before they achieve it. We want systems whose plots are visible to inspection.
The Narrative-Driven Architecture provides this transparency not as an afterthought but as a core feature. A system that must maintain an explicit Narrative Arc is a system that has an articulable intention at every moment. It is a system that can, if queried, produce a genuine villain’s monologue—or, hopefully, a hero’s statement of purpose.
This transparency is not sufficient for safety, but it is necessary. We cannot align what we cannot understand. Narrative architecture makes understanding possible.
7. Conclusion: Intelligence as Compression
We began with a dishwasher and end with a question: What is intelligence?
We suggest that intelligence, at its core, is a mechanism for compressing experience into actionable narrative. When a human child learns that fire is dangerous, they do not store the raw sensory data of every encounter with flame. They construct a story: “Fire burns. I touched it once. It hurt. I won’t touch it again.” This story compresses countless potential experiences (all possible future encounters with fire) into a simple predictive model (fire → pain → avoid).
Current AI systems pursue the opposite strategy. They attempt to achieve intelligence through expansion: larger models, longer context windows, more training data. This approach has yielded remarkable results, but we believe it represents a ceiling rather than a trajectory. There is no context window large enough to contain all possible situations a general intelligence might encounter. There is no training dataset comprehensive enough to anticipate every edge case.
What is needed is not more memory but better compression. Not larger windows but better stories.
The Narrative-Driven Architecture we have outlined represents one possible approach to this compression problem. By building world-state simulation, goal hierarchies, and temporal structure into the foundation of AI systems, we create the architectural preconditions for genuine teleological reasoning—for systems that understand not just what to do next but why.
Moreover, we have argued that this narrative approach offers profound advantages for AI safety. By making intentions explicit and endings auditable, we create systems whose alignment can be verified rather than merely hoped for. The goal hierarchy provides a natural home for inviolable safety constraints. The three-act structure enables prospective reasoning about harmful trajectories. The transparency of narrative cognition allows for meaningful oversight.
We make no claim that this approach is sufficient for AGI, nor that it resolves all concerns about AI safety. But we do claim that some approach in this direction is necessary—for both capability and safety reasons. The attention mechanism solved the problem of reading. The problem of thinking remains open. And the problem of thinking safely cannot even be properly posed until we have systems with legible intentions.
If attention is the mechanism of reading, story is the mechanism of thinking.
And if we wish to build machines that think wisely, we must build machines that can recognize a tragedy before it unfolds—and choose a different ending.
References
Vaswani, A., et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press.
Tulving, E. (1972). Episodic and Semantic Memory. In Organization of Memory (pp. 381–403). Academic Press.
Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems, 35.
Dennett, D. C. (1987). The Intentional Stance. MIT Press.
Bruner, J. (1991). The Narrative Construction of Reality. Critical Inquiry, 18(1), 1–21.
Bostrom, N. (2014). Superintelligence: Paths, Dangers, Strategies. Oxford University Press.
Russell, S. (2019). Human Compatible: Artificial Intelligence and the Problem of Control. Viking.
Christiano, P., et al. (2017). Deep Reinforcement Learning from Human Feedback. Advances in Neural Information Processing Systems, 30.
Hadfield-Menell, D., et al. (2016). Cooperative Inverse Reinforcement Learning. Advances in Neural Information Processing Systems, 29.
The idea that intelligence is compression rather than expansion really clicks. Current LLMs basically try to memorize everything instead of abstracting the key patterns like humans do with episodic memory. Your example of remembering 'fire burns' as a compressed story instead of raw sensory data from every encounter makes the point super clear. It's interesting that Chain-of-Thought basically tricks models into building temporary narratives, but you're right that baking this structure directly into the architecture would be way more robust than relying on prompts to coax it out.